
안녕하세요, 루피입니다!
오늘은 캐시 메모리에 대해 정리해 보는 시간을 가져보겠습니다. 저번 주기억 장치에 관한 글을 읽고 오시면, 더 쉽게 이해되실 겁니다.
바로 시작합니다.
1. 캐시 메모리란?
캐시 메모리는 CPU와 주기억장치(RAM) 사이에 위치한, 용량은 작지만 속도가 매우 빠른 메모리입니다. CPU의 연산 속도는 눈부시게 빠른데, 주기억 장치의 속도는 그에 미치지 못하죠. 캐시 메모리는 바로 이 둘 사이의 속도 차이를 극복하기 위해 존재합니다.
CPU는 데이터를 찾을 때, 느린 주기억 장치까지 가기 전에 먼저 빠른 캐시 메모리를 확인합니다.
1.1) 캐시의 기본 동작
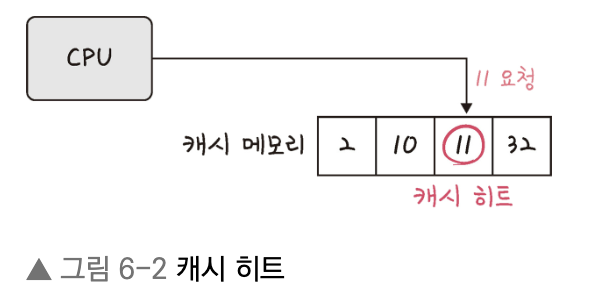
CPU가 캐시 메모리를 뒤졌을 때, 원하는 데이터가 있느냐 없느냐에 따라 두 가지 상황이 발생합니다.
- 캐시 히트 (Cache Hit): CPU가 요청한 데이터가 캐시 메모리에 존재하는 경우입니다. 이 경우 CPU는 데이터를 매우 빠른 속도로 가져와 작업을 수행할 수 있습니다. 히트율(Hit Rate)이 높을수록 성능이 향상됩니다.
- 캐시 미스 (Cache Miss): 반대로 요청한 데이터가 캐시 메모리에 존재하지 않는 경우입니다. 이럴 땐 어쩔 수 없이 더 느린 주기억 장치까지 가서 데이터를 가져와야 합니다.

1.2) 캐시 메모리의 종류
캐시는 CPU와의 근접성과 속도에 따라 여러 레벨로 나뉩니다.
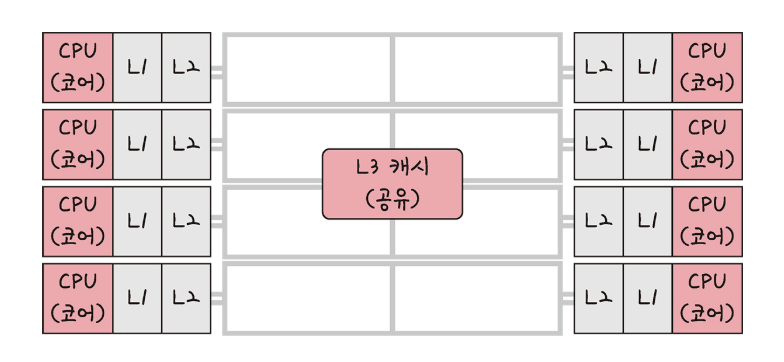
- L1 캐시: CPU 코어에 가장 가까이 위치하며 속도가 가장 빠릅니다.
- L2 캐시: L1 캐시보다는 크고 약간 느립니다. L1에서 찾지 못한 데이터를 저장하는 데 사용됩니다.
- L3 캐시: L1, L2보다 용량이 더 크고 속도는 더 느립니다. 여러 CPU 코어가 함께 사용하는 공용 캐시로, 데이터 공유와 일관성 유지에 중요한 역할을 합니다.
CPU는 L1 → L2 → L3 → 주기억장치 순서로 데이터를 찾아 나갑니다.
2. 지역성
캐시 메모리는 용량이 매우 작기 때문에 어떤 데이터를 저장할지 잘 선택해야 합니다. 이 선택의 기준이 되는 것이 바로 지역성(Locality)의 원리입니다. 프로그램의 메모리 접근 패턴은 예측 가능한 경향이 있다는 것이죠.
- 시간 지역성 (Temporal Locality): "한 번 사용한 데이터는 가까운 미래에 다시 사용될 가능성이 높다"는 원리입니다.
- 공간 지역성 (Spatial Locality): "하나의 데이터에 접근하면, 그 근처에 있는 데이터에도 곧 접근할 가능성이 높다"는 원리입니다.
캐시는 이 원리를 바탕으로 CPU가 다음에 필요할 만한 데이터를 미리 가져다 놓아 히트율을 높입니다.
3. 캐시 메모리 관리
3.1) 캐시 교체 정책
캐시가 꽉 찼을 때 새로운 데이터를 넣으려면 기존 데이터를 제거하고 새로운 데이터를 저장해야 합니다.
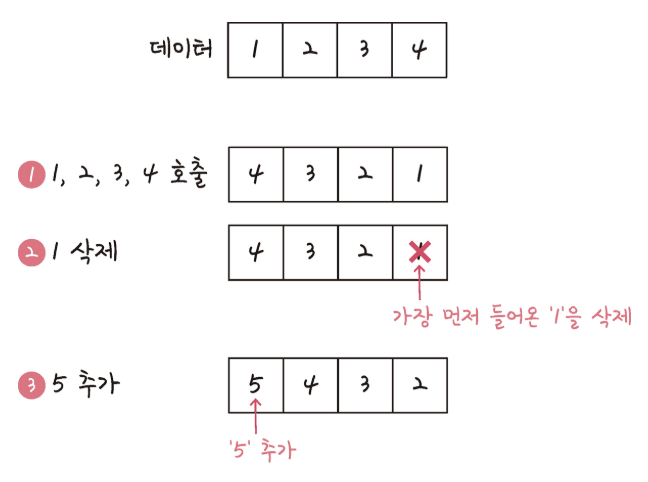
1. LRU (Least Recently Used): 가장 오랫동안 사용되지 않은 데이터를 교체합니다.
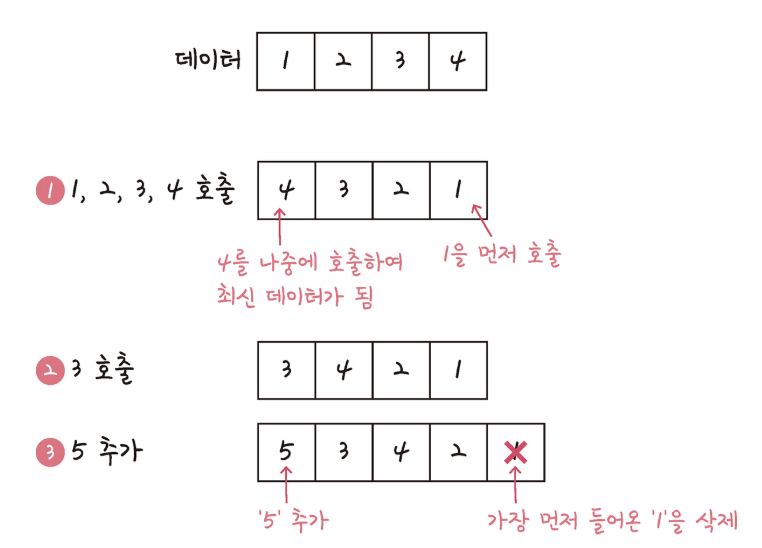
2. FIFO (First In, First Out): 가장 먼저 들어온 데이터를 교체합니다.
3. LFU (Least Frequently Used): 사용 빈도가 가장 낮은 데이터를 교체합니다.

4. 무작위 (Random): 임의의 데이터를 교체합니다.

3.2) 쓰기 정책
CPU가 캐시의 데이터를 수정했을 때, 이를 언제 주기억 장치에 반영할지 결정합니다.
- 즉시 쓰기 (Write-Through): 캐시와 주기억 장치에 동시에 씁니다. 데이터 일관성 유지가 쉽지만 속도는 조금 느립니다.
- 지연 쓰기 (Write-Back): 우선 캐시에만 쓰고, 해당 데이터가 캐시에서 교체될 때 나중에 주기억 장치로 옮깁니다. 쓰기 성능이 좋지만 데이터 일관성 관리가 더 복잡합니다.
3.3) 할당 정책
- 요구 시 가져오기 (Demand Fetching): 캐시 미스가 발생했을 때만, 해당 데이터를 주기억 장치에서 가져옵니다.
- 사전에 가져오기 (Prefetching): 앞으로 필요할 것으로 예상되는 데이터를 미리 캐시에 가져다 놓습니다.
4. 캐시 메모리 매핑
주기억 장치에 저장된 명령어/데이터가 캐시 메모리에 저장되어야 하는 상황은 빈번히 발생합니다. 하지만, 문제가 있습니다.
바로 캐시 메모리의 주소와 주 기억 장치의 주소가 다르다는 것입니다.
이때, 캐시 메모리 매핑은 메인 메모리의 명령어 및 데이터가 캐시 메모리에 어떻게 저장되는지를 결정하는 방식입니다.
이 기술은 CPU가 메인 메모리에 있는 데이터에 더 빠르게 접근할 수 있도록 도와줍니다.
4.1) 저장 단위
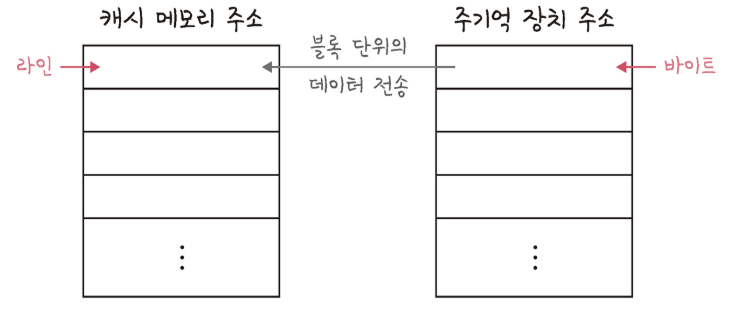
- 캐시 메모리는 데이터를 라인(Line) 또는 블록(block) 단위로 저장합니다.
- 메인 메모리는 데이터를 바이트(byte) 단위로 저장합니다.
- 데이터는 메인 메모리에서 캐시로 블록 단위를 전송됩니다.
4.2) 주소 구조
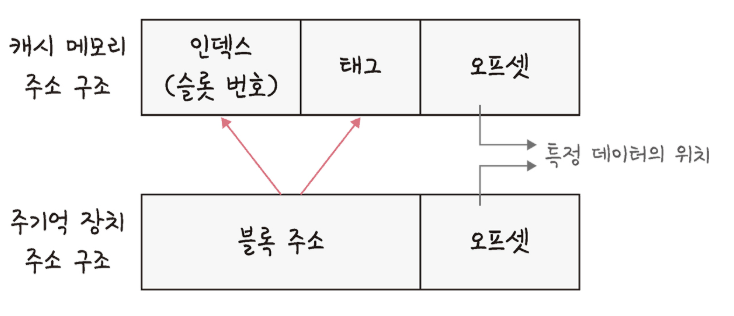
- 메인 메모리 주소는 일반적으로
블록 주소와바이트로구성됩니다. - 캐시 메모리 주소는
태그, 인덱스, 오프셋으로구성됩니다.- 인덱스 : 캐시 메모리 내의 특정 라인(슬롯 번호)을 나타냅니다. CPU가 어떤 데이터가 캐시에 있는지 찾을 때, 인덱스를 사용하여 해당 라인을 찾습니다.
- 태그 : 메인 메모리 주소의 일부로, 캐시 라인에 저장된 데이터가 메인 메모리의 어느 블록에서 왔는지를 식별합니다.
- 오프셋: 캐시 라인 내에서 특정 데이터의 위치(바이트 단위)를 나타냅니다.

4.3) 데이터 매핑 과정
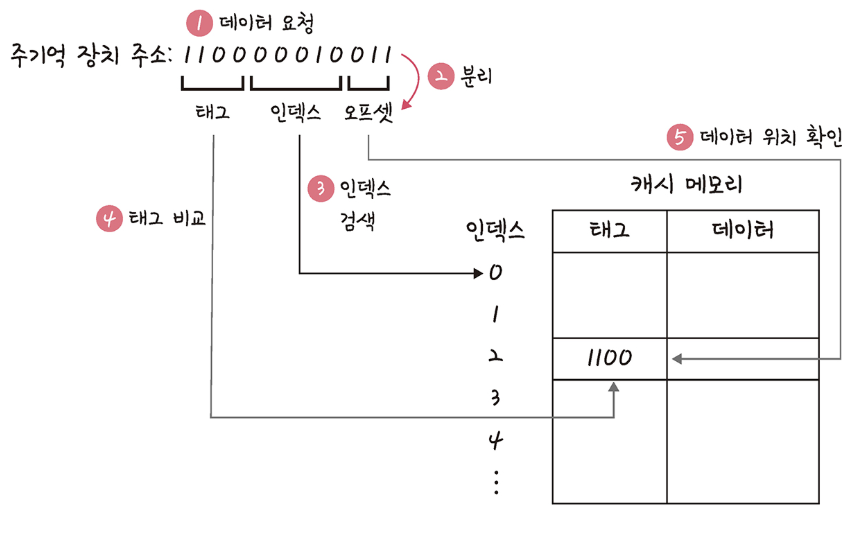
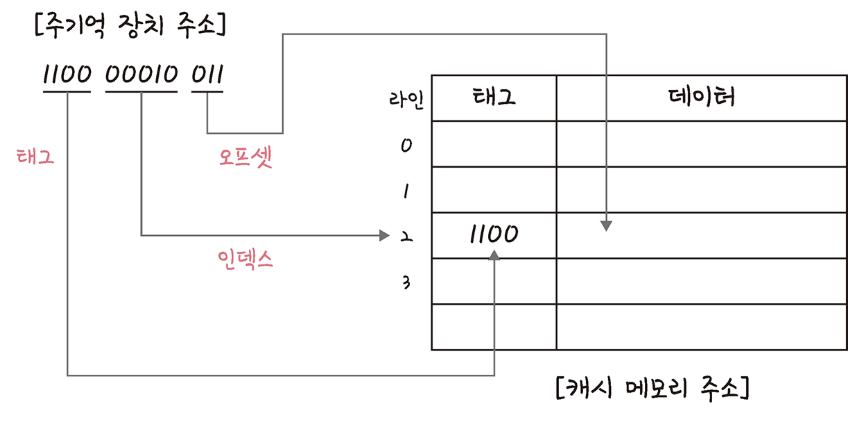
- 데이터 요청: CPU가 메인 메모리에서 특정 데이터를 요청할 때, 해당 메인 메모리 주소를 사용합니다.
- 주소 분할: 메인 메모리 주소는 태그, 인덱스, 오프셋 부분으로 나뉩니다.
- 인덱스 검색: 분할된 주소의 인덱스를 사용하여 캐시 메모리 내의 해당 라인을 찾습니다.
- 태그 비교: 찾은 캐시 라인에 저장된 태그와 요청된 메인 메모리 주소에서 추출한 태그를 비교합니다.
- 데이터 확인 (캐시 히트):
- 만약 두 태그가 일치한다면, 요청된 데이터가 캐시에 존재한다는 의미이며 이를 캐시 히트(Cache Hit)라고 합니다. 이 경우 CPU는 캐시에서 해당 데이터를 오프셋을 사용하여 직접 가져와 매우 빠르게 처리할 수 있습니다.
- 데이터 없음 (캐시 미스):
- 만약 태그가 일치하지 않거나 해당 데이터가 캐시에 없다면, 이는 캐시 미스(Cache Miss)를 발생시킵니다.
- 캐시 미스가 발생하면 CPU는 메인 메모리에서 해당 데이터를 찾아 캐시로 가져옵니다. 이때 캐시 관리 정책(예: LRU, FIFO, LFU)에 따라 기존의 캐시 데이터를 교체하고 새로운 데이터를 캐시에 저장합니다.
5. 데이터 동기화
캐시에 저장된 데이터와 주기억장치의 데이터가 항상 같지는 않습니다. 이 둘의 상태를 맞추기 위한 관리 작업이 바로 캐시 플러시와 캐시 클린입니다.
5.1) 캐시 플러시
캐시 플러시는 캐시 메모리에 저장된 모든 내용을 주기억장치에 쓰고, 캐시를 깨끗하게 비워 초기 상태로 되돌리는 과정입니다. 주로 컴퓨터를 안전하게 종료하거나 재부팅하기 전에 모든 변경 사항을 주기억장치에 안전하게 저장해야 할 때 사용됩니다.
진행 과정은 다음과 같습니다.
- 캐시 내의 각 라인을 검사하여 더티 데이터(dirty data)가 있는지 확인합니다. 더티 데이터란 캐시에는 수정되었지만 아직 주기억장치에는 반영되지 않은 데이터를 의미합니다.
- 더티 데이터가 있다면, 이 데이터를 주기억장치에 씁니다.
- 캐시의 모든 데이터가 주기억장치로 쓰인 후, 캐시 메모리는 초기화되어 모든 라인이 빈 상태가 됩니다.
5.2) 캐시 클린 (Cache Clean)
캐시 클린은 캐시 플러시와 약간 다릅니다. 캐시 클린은 더티 데이터만 주기억장치로 써서 데이터를 동기화하지만, 캐시의 내용을 비우지는 않습니다. 즉, 이미 주기억장치와 동기화된 데이터는 그대로 캐시에 남겨두고 계속 사용할 수 있게 하는, 좀 더 효율적인 동기화 방식입니다.
오늘도 화이팅입니다!!
'CS' 카테고리의 다른 글
| [CS] Swift로 HashMap 구현하기 (2) | 2025.07.11 |
|---|---|
| [CS] Swift로 AST 구현하기(with SIL) (1) | 2025.07.10 |
| [CS] 5. 주기억 장치 (0) | 2025.07.01 |
| [CS] 4. CPU 동작원리 (0) | 2025.06.20 |
| [CS] 3. 컴퓨터의 명령어 처리 방식 (0) | 2025.06.15 |